There is a scene in Interstellar that I have seen multiple times and still not over it. Cooper, having plunged into a black hole, finds himself inside a structure made of infinite bookshelf corridors. The effect of light streaming through the slats and time bending into something he can physically touch is simply… spectacular!
The monolith-like beings have given him a tesseract. Not as a gift but as a tool, it’s a multi-dimensional interface to navigate information across time and space. He reaches through the shelves and nudges gravitational data into the past, communicating with his daughter across a dimension that shouldn’t otherwise be accessible.
That scene made me lean forward in my seat and I was like, what IS that thing, actually? Not the plot device, the geometry.
The idea of a structure that contained more than three dimensions, that folded space and time into something you could manipulate with your hands is extremely overpowering yet beautiful.
I live in research papers, I read them, visualize them and marinate for days and in my understanding how modern AI systems and scientific computing work, I’ve started to realise one thing, the tesseract is not just a mathematical curiosity or a Christopher Nolan set piece. It’s becoming one of the most important conceptual frameworks in how we handle data at scale.
The hypercube, that 4D shape that loops a cube inside a cube and connects every corner, is the secret geometry behind some of the most powerful and genuinely exciting computational systems being built right now.
In Madeleine L’Engle’s 1962 novel A Wrinkle in Time, Mrs. Whatsit describes a tesseract as “a wrinkle in time”, a fifth-dimensional shortcut that folds space so that instead of travelling from A to B, you bring A and B together. A similar idea is visualised in Interstellar, where the crew travels through a wormhole near Saturn, rather than moving conventionally through space, they pass through a higher-dimensional shortcut that collapses vast cosmic distances into a traversable passage.
Isn’t that, in essence, what modern tensor data structures do to information?
First, Let Me Ground This in Geometry
A tesseract, in the strictest mathematical sense, is a four-dimensional hypercube. You start with a point.
Extend it in one direction and you get a line.
Extend the line perpendicularly and you get a square.
Extend the square perpendicularly and you get a cube.
Now extend that into a fourth spatial dimension, and what you get is a tesseract:
a cube inside a cube, their eight corners connected by spokes of geometry that simply cannot exist in our physical world.
The way it’s usually rendered in 3D, with two nested cubes connected at the corners, it kind of confuses me. It looks like something bigger that’s been squeezed into a shape I can actually see. Like it’s trying to exist in more dimensions, but has to settle for something my eyes can understand. Almost like when you try to explain music using words, you get the idea across, but it never feels like the real thing.
I’d like to think it like this:
- A single number is just… a number. Nothing to move through.
- A list is like a row, you can go left and right.
- A table is like a spreadsheet, you can go left/right and up/down.
- A cube is like stacking spreadsheets, you can also go forward/backward.
Now here’s the part that sounds weird:
What if you had one more direction to move in… but it’s not something you can see?
That’s all a “fourth dimension” really means here. Not something mystical, just one extra way to organize and access data.
So instead of thinking:
“This is some crazy 4D object”
Think:
“This is just data where I need four different labels to find something”.
For example:
- In a spreadsheet (2D), you find a value using: row + column
- In a cube (3D), you might use: row + column + layer
- In a “tesseract” (4D), you just add one more:
row + column + layer + something else
That “something else” could be:
- time
- different sensors
- versions of data
- categories
So when people say “tesseract” in computing, they don’t mean a sci-fi shape floating in space, they just mean:
“Data that needs four coordinates to locate anything”.
It looks complicated only because we try to draw it. But computers don’t care what it looks like, they just follow coordinates.
So really, a tesseract isn’t something you have to visualize.
It’s something you index.
| Representation | Common Name | Tensor Form | Dimension |
| A single number | Scalar | 0D tensor | 0D |
| A list | Vector | 1D tensor | 1D |
| A table | Matrix | 2D tensor | 2D |
| A cube of numbers | — | 3D tensor | 3D |
| A 4D version (tesseract) | Tesseract | 4D tensor | 4D |
The key idea: “Tensor” = anything with multiple dimensions of data
The first time, the geometry clicked for me was when I stopped trying to see the tesseract and started thinking about how I was already using it.
We all work with the LLMs in various capacities, lets’ say you’re working with a model that didn’t just take in images, but sequences of images over time, layered with probabilities and context, and gradually the data stopped feeling like a flat table or even a stack of tables. It felt… navigable. Like each axis wasn’t just “more data”, but a different way of asking a question, where, when, what, how likely.
And instead of forcing everything into rows and columns, the system was moving through these axes as if they were directions in space. That’s when I could connect the dots with the bookshelf scene from Interstellar. Cooper wasn’t looking at time, he was indexing into it. He wasn’t traveling, he was traversing dimensions. And in that moment, I felt the tesseract isn’t an abstraction and became almost familiar:
a structure where complexity isn’t reduced, but organized, so you can finally move through it.
Training AI on a Tesseract
Modern AI models like GPT or Gemini sound incredibly complex, but at a basic level, they’re just doing a lot of operations on these things called tensors, which, as we just saw, are basically multi-dimensional blocks of data.
You can think of each layer in a neural network like a step in a process, it takes in some structured data, reshapes or mixes it (mostly using matrix math), and passes it on. Over and over again. Nothing extraordinary, just repeated transformations of data.
The problem starts when the models get really big.
A powerful GPU today might have something like 80 GB of memory, which sounds like a lot, until you realize modern AI models can have hundreds of billions of parameters. At that point, it’s like trying to fit an entire library into a single backpack. It just doesn’t go.
So the real question becomes less about the math and more about logistics:
- How do you break this huge “block of data” (these tensors) into smaller pieces and spread them across lots of GPUs…without spending all your time just moving data back and forth between them?
Because if the communication between machines becomes too heavy, everything slows down, and all that power doesn’t help anymore.
A 2021/2022 paper from Colossus (presented at ICPP’22) titled Tesseract: Parallelize the Tensor Parallelism Efficiently addresses exactly this. The researchers, Boxiang Wang and colleagues, proposed a method called Tesseract that introduced a new dimension into how tensor operations are distributed across GPUs.
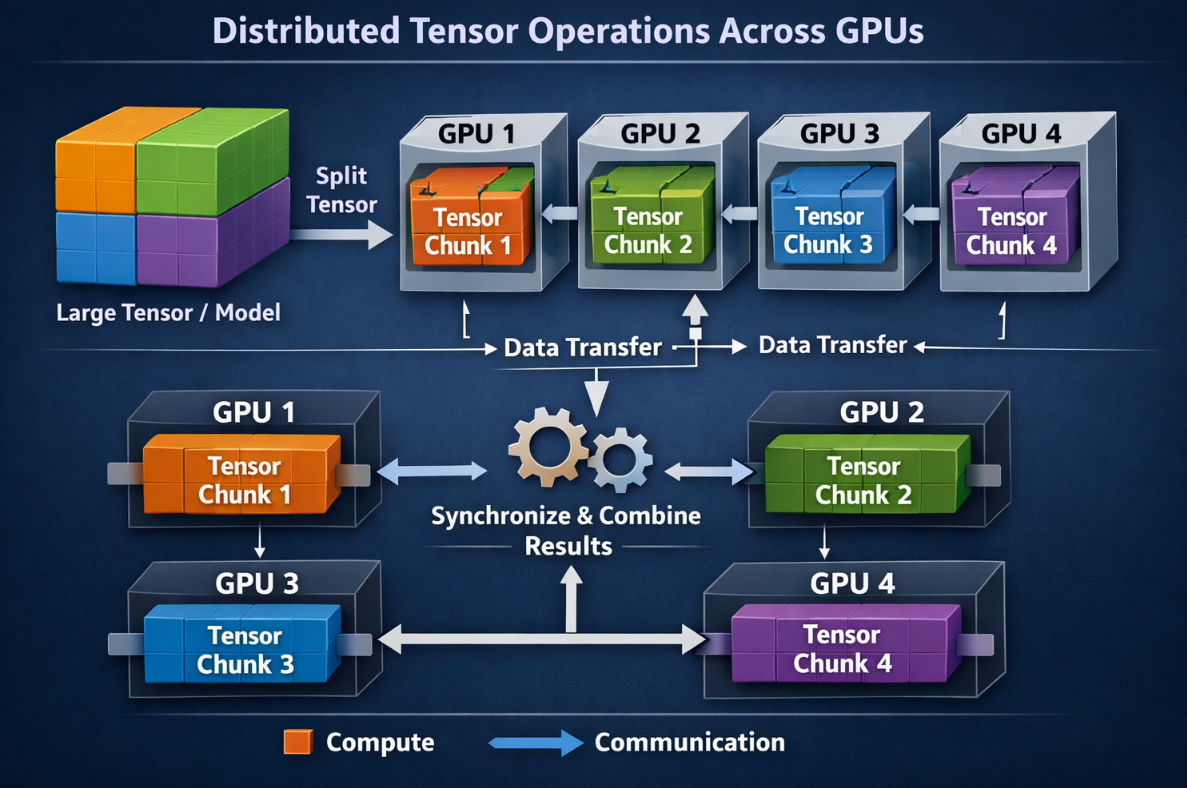
Before this, most approaches were kind of one-dimensional. Imagine you have a big block of data and you just slice it in one direction, like cutting a loaf of bread. Each GPU gets one slice.
What Tesseract does differently is simple (at least conceptually), instead of slicing in just one direction, it slices in two directions.
So now, instead of a single line of GPUs, you can think of them arranged like a grid, rows and columns, like a table. And the data gets split across both directions.
It’s like the difference between:
- handing out pages of a book one by one
vs - laying the pages out in a grid so multiple people can work on different parts more efficiently
That small shift, adding one more “direction” to how things are split, actually makes a big difference.
The result is that things actually start to scale the way you’d hope, they run faster, more smoothly, and without getting bogged down by constant back-and-forth between GPUs, which is usually where everything falls apart.
And this is where it gets interesting again,
we started with the idea of higher dimensions as something abstract…and now ended up using an extra “direction” as a very practical way to make these massive systems work.
What I find kind of beautiful about this, at least the way I’m starting to see it, is that it’s not just a metaphor. It’s actually geometry showing up in computing in a very real way.
To train a really big model, you’re dealing with more data than any single GPU can handle. So instead of forcing one machine to do everything, you sort of spread the problem out across many GPUs. And when you arrange them in a grid (or even more complex layouts), it’s almost like each one is handling a small piece of a much bigger, higher-dimensional structure.
I don’t fully “see” a tesseract in my head, but I can kind of imagine this,
Each GPU is holding one part of something bigger, and together they form a system that can handle what none of them could on their own.
And that’s where it connects back to the wrinkle-in-time idea from A Wrinkle in Time.
Instead of one smaller computer slowly grinding through a massive model step by step, you sort of fold the work across space, so many parts happen at once. What would have taken forever starts to happen much faster.
So the “tesseract” here isn’t just some abstract container.
It starts to feel more like a shortcut.

The Multi-Agent Problem: When Many Minds Must Think as One
Now let me take you to a completely different application of the same geometry, and one that connects to another sci-fi classic I love.
Remember in Ender’s Game, a fleet of ships, each with an individual pilot, needing to act as one coordinated swarm against an alien enemy. The challenge isn’t intelligence, each pilot has it. The challenge is shared decision-making at scale. How do you decide what’s best for the whole when each agent only sees part of the picture?
This is the core problem of cooperative multi-agent reinforcement learning (MARL). Just think about it, you have thirty robots on a warehouse floor, all making decisions simultaneously, each robot has its own set of possible actions. The optimal action for robot 7 depends on what robots 1 through 30 are doing. The number of combined action possibilities explodes exponentially, you quickly reach a number so large it becomes computationally intractable to model the value of any given joint decision.
A research paper presented at ICML 2021 by Anuj Mahajan and colleagues titled Tesseract: Tensorised Actors for Multi-Agent Reinforcement Learning tackles this directly.
If you try to list out every possible combination of what all the agents could do together, the list becomes ridiculously huge, basically impossible to work with.
The idea in the paper is, instead of storing everything as one long, messy list, store it as a tensor.
So now, instead of:
- one giant list of all possibilities
you have:
- a multi-dimensional structure where each dimension represents one agent’s choices
That already makes things a bit more organized.
But even then, it’s still too big.
So they take it one step further, they approximate this giant tensor using smaller pieces. It’s like saying,
“we don’t need every tiny detail, we just need the parts that actually matter”.
The result is that each agent doesn’t have to understand everything about everyone else. It only needs to capture the important interactions.
And surprisingly, this still works really well. In fact, the paper shows that the method can be learned efficiently and reliably over time.
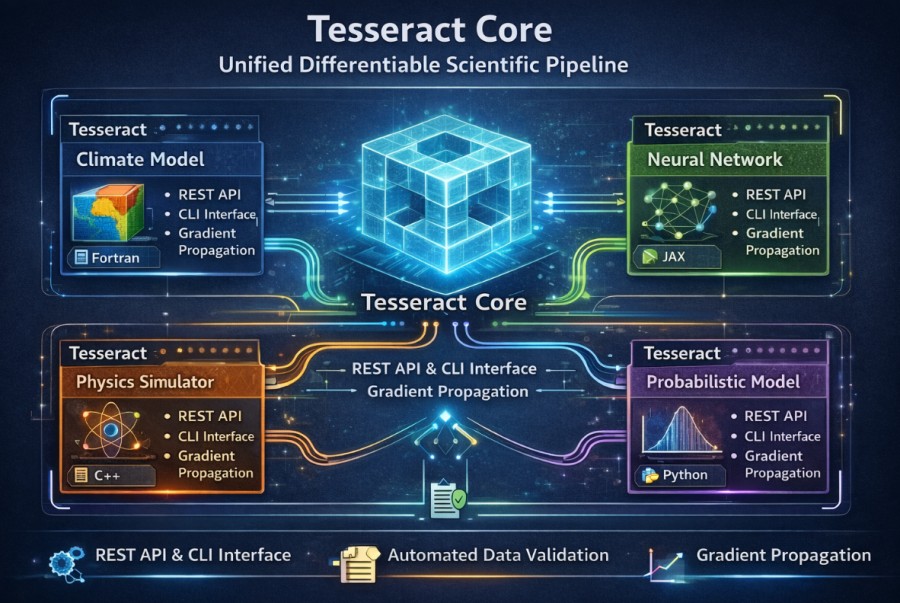
Tesseract Core Turns Disconnected Tools into One System
Last year, the thing that made me filled with awe was (and still is) the Tesseract Core by Pasteur Labs.
It’s idea is, you take any piece of scientific software, doesn’t matter what language it’s written in or what framework it uses, and you wrap it into this neat, self-contained unit called a “Tesseract”.
Once it’s wrapped, it becomes much easier to work with. It exposes a simple API (basically a clean way to talk to it), can be run from the command line, and even checks that the data going in and out is in the right format.
Now, I’m not super deep into the math here, but the rough idea is this, if you connect a bunch of these Tesseracts together into a pipeline, you can still treat the whole thing like one system and optimize it end-to-end. Even if:
- one part is written in Python
- another is running somewhere else
- another is on completely different hardware
you can still “flow” information backward through all of it and improve the whole pipeline together.
So instead of a bunch of disconnected tools glued together awkwardly, it starts to feel like one continuous system.
Which is kind of wild because these pieces weren’t designed to work together in the first place.
TesserAct: Now We’re Building 4D World Models
By mid-2025, researchers at UMass published TesserAct: Learning 4D Embodied World Models, it’s an open-source system for training robots by having them predict not just what a scene looks like now, but what it will look like in the future, in three spatial dimensions, as time evolves.
The model takes an image and a text instruction, let’s say, “pick up the red cup”, and generates a video that predicts RGB colour, depth, and surface normals for every frame of the predicted action. Depth and normals together let you reconstruct the geometry of the scene in three dimensions. Add time, and you have a 4D prediction, a model of how the physical world evolves in response to an agent’s actions.
This is, quite literally, what Cooper’s tesseract was doing in Interstellar, giving him the ability to perceive and interact with events across a four-dimensional structure, (three spatial dimensions plus time) from a vantage point that transcended his own moment in it. TesserAct does the same thing for a robot arm. It doesn’t just see the cup. It sees the cup across the trajectory of the action it’s about to take, with geometric fidelity, before the action happens.
The model was built on top of CogVideoX and fine-tuned on robotic manipulation videos augmented with depth and normal information. It achieves better generalisation than 2D prediction models precisely because the additional dimensionality gives it richer constraints, depth prevents the model from hallucinating physically impossible configurations, normals give it a sense of surface orientation that pure colour images lack.

When I Let Myself Speculate
The trajectory I see is, we are building computing infrastructure that increasingly treats high-dimensional data not as a problem to be flattened away, but as a native environment to navigate.
- Tesseract-style tensor parallelism means our biggest models can train on distributed hardware without becoming communication bottlenecks.
- Tesserised MARL means we can build swarms of autonomous agents that act coherently at scales humans can’t directly supervise.
- Tesseract Core means we can build scientific pipelines that span physics, chemistry, biology, and AI, and optimize them together, end-to-end, as if they were a single differentiable system.
- TesserAct means we’re building robots that predict the four-dimensional geometry of the world before they move through it.
If you put all of this together, it starts to feel like we’re at the beginning of something big. Maybe, in the future, people will look back and say this was the point where computing stopped being flat and started becoming more… spatial. Not just rows and columns anymore, but something with multiple dimensions. Systems that are built in a way that actually matches the complexity of the problems they’re trying to solve.
What I’m trying to say is, instead of squeezing complex, multi-dimensional problems into flat tables or 2D formats, we’re starting to build systems that actually work in those higher dimensions naturally. And when you think about it like that, it feels a bit like what Cooper does in Interstellar, not just observing time, but moving through it, interacting with it in ways that wouldn’t normally be possible.
With this I can say with audacity that whether you’re distributing a trillion-parameter model across a thousand GPUs, training thirty warehouse robots to act as a coherent unit or building a system that connects spreadsheets and machine learning models, you are, in a real sense, learning to move through a tesseract.
The hypercube has been hiding in the architecture the whole time. We’re just now learning to live inside it.
Referenced Research & Further Reading
Tesseract Core — ACM Digital Library
Tesseract: Parallelize the Tensor Parallelism Efficiently (Wang et al., 2021/2022)
Tesseract: Tensorised Actors for Multi-Agent RL (Mahajan et al., ICML 2021)
TesserAct: Learning 4D Embodied World Models (Zhen et al., 2025)
Tesseract Core — Journal of Open Source Software (Häfner & Lavin, 2025)
Neural Nets in Tesseract 4.0 — Official Documentation
Tesseract and Time Travel — BYU 4th Wall Dramaturgy
Hybrid LSTM-DNN with Hypercube Sampling — MDPI Processes